Pull requests form a new method for collaboration on distributed software
development. The novelty lays in the decoupling of the development effort from
the decision to incorporate the results of the development in the code base.
Several code hosting sites, including Github and
BitBucket, tapped on the opportunity to make the
pull-based development model more accessible to programmers. A unique
characteristic of such sites is that they allow any user to fork any public
repository. The clone creates a public project that belongs to the user that
cloned it, so the user can modify the repository without being part of the
development team. What is more important is they automate the selective
contribution of commits from the clone to the source, through pull requests.
Pull requests are not unique to code hosting sites; in fact, the Git version
control system includes the git-request-pull utility, which provides the same
functionality at the command line. Github improved (not everyone
agrees) this process significantly
by integrating code reviews, discussions and issues, thus effectively lowering
the entry barrier for casual contributions. Combined, cloning and pull requests
create a new development model, where changes are pushed to the project
maintainers and go through code review by the community before being integrated.
A year ago, together with Martin
Pinzger and Arie van
Deursen, we set forth to explore how this new and
exciting way of building software in a distributed manner actually works under
the wraps. How widespread is the use of pull requests? What are the
characteristics of the pull request lifecycle? What factors play a role in the
decision to merge and the time to process pull requests? Why are some pull
requests not merged?
The dataset we used to do this study was based on
our
previous
work on GHTorrent, a
queriable off-line
mirror of the data offered through the Github
API. The project has been collecting data since February 2012. Up to August
2013, when this study was conducted, 1.9 million pull requests from more than
200k projects have been collected.
Here is what we learned.
Use of pull requests on Github
In August 2013, Github reported more than 7 million repositories and 4 million
users. However, not all those projects are active: in the period Feb 2012 — Aug
2013, the GHTorrent dataset captured events initiated by (approximately)
2,281,000 users affecting 4,887,500 repositories. The majority of registered
repositories are forks of other repositories, special repositories hosting user
web pages, program configuration files and temporary repositories for evaluating
Git. In the GHTorrent dataset, less than half (1,877,660 or 45%) of the active
repositories are original repositories.
Of course, not all repositories on Github use pull requests. In fact, only 32%
of the repositories actually have more than one contributor. To get an estimate
of the popularity of pull requests among those repositories, we compared the use
of pull requests on Github in the same periods across two consecutive years (Feb
to Aug 2012 and 2014). We also included the number of repositories that use the
shared repository approach exclusively. The results can be seen in the table
below:
| Metric |
Feb-Aug 2012 |
Feb-Aug 2013 |
| Active repos (> 1 commits) |
315,522 (100%) |
1,157,625 (100%) |
|
|
|
| Repos with 1 contributor |
261,317 (65%) |
913,205 (79%) |
| Repos with pull requests |
53,866 (17%) |
120,104 (10%) |
| Repos with shared repository |
54,205 (18%) |
124,316 (11%) |
</table>
If nothing else, this table is representative of the staggering growth of
Github. The number of public repos with visible activity grew more that 3x in
just one year. The number of collaborative repos grew 2.4x times, which means
that the relative number of repos using either the shared repository model
exclusively or pull requests decreased. On both years, an equal proportion of
repositories use either pull requests or the shared repository model.
For those projects that received pull requests in 2013, the mean number of pull
requests per project is relatively low at 8.1 (median: 2, percentiles: 5%: 1,
95%: 21); however, the distribution of the number of pull requests in projects
is highly skewed. In case you think that popular projects get the most pull
requests, you are wrong: this is only weakly supported by our data. From the
pull requests that have been opened in 2013, 73,07% have been merged using
Github facilities (more might have been merged using other methods, see below).
**summary:** *~14% of repositories are using pull requests on Github. Pull
requests and shared repositories are equally used among projects.*
### Characteristics of the pull request lifecycle
 The GHTorrent dataset is good to get an overall view of pull requests across all
projects on Github, but we wanted to go deeper than that. For this reason, we
selected all projects written in Ruby, Python, Java and Scala (why just those
languages? because testing detection is possible) that had more than >200 pull
requests in their lifetime and using a combination of GHTorrent and their Git
repositories, we extracted more than [40
features](https://github.com/gousiosg/pullreqs#generating-intermediate-files)
for each pull request. We also applied heuristics to detected merges happening
outside Github (e.g. using `git merge`, `git rebase`, cherry-picking etc).
This brought the number of merged pull requests up to 84%. In total, we
analyzed 291 software development projects (99 Python, 91 Java, 87 Ruby, 14
Scala) and 166,884 pull requests.
We then analyzed the generated data in various dimensions, in order to identify
the lifecycle characteristics of pull requests and determine the factors that
influence them.
**Lifetime**
The GHTorrent dataset is good to get an overall view of pull requests across all
projects on Github, but we wanted to go deeper than that. For this reason, we
selected all projects written in Ruby, Python, Java and Scala (why just those
languages? because testing detection is possible) that had more than >200 pull
requests in their lifetime and using a combination of GHTorrent and their Git
repositories, we extracted more than [40
features](https://github.com/gousiosg/pullreqs#generating-intermediate-files)
for each pull request. We also applied heuristics to detected merges happening
outside Github (e.g. using `git merge`, `git rebase`, cherry-picking etc).
This brought the number of merged pull requests up to 84%. In total, we
analyzed 291 software development projects (99 Python, 91 Java, 87 Ruby, 14
Scala) and 166,884 pull requests.
We then analyzed the generated data in various dimensions, in order to identify
the lifecycle characteristics of pull requests and determine the factors that
influence them.
**Lifetime**
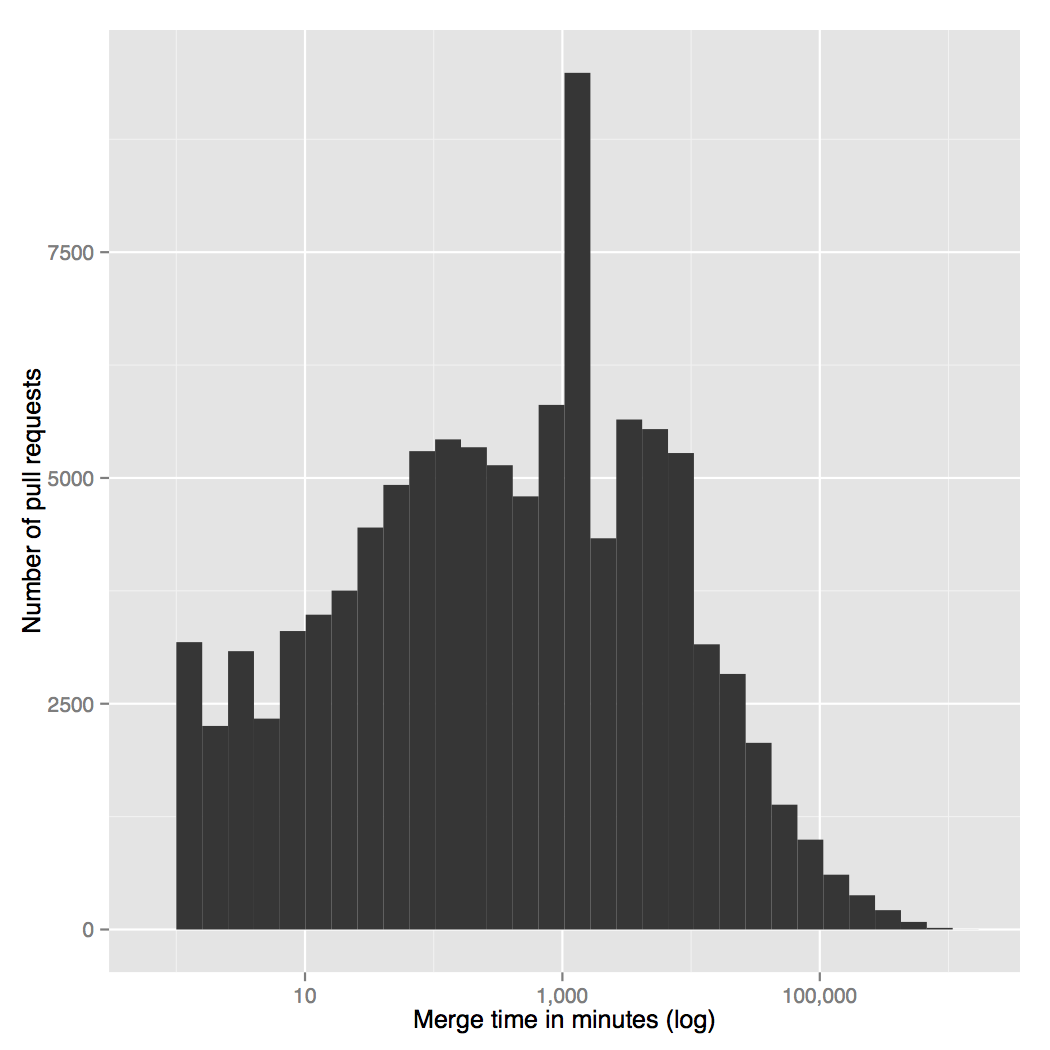 By correlating pull request features with the time to merge and the
time to close pull requests, one can find very interesting patterns.
Here is a list of our most interesting findings:
* The time to merge pull requests is highly skewed, as can be seen in the
figure above, with the great majority of merges happening very fast. Measured in
days, 95% of the pull requests are merged in 26, 90% in 10 and 80% in 3.7 days.
30% of the pull requests are merged in under one hour!
* Pull requests are either merged fast or left open lingering before they are
* closed. Pull requests received no special treatment, irrespective whether
* they came from core team members or from the community, as there is
no statistical significant difference in the time required to close both.
* The time required to merge pull requests is not correlated with
the project's size, but it is correlated with the pull requester's track record.
The more pull requests that have been accepted by a specific developer, the
faster his/her new pull request will be processed. This is an indication that
eventually even software developers can learn to trust each other :-)
**Size**
By correlating pull request features with the time to merge and the
time to close pull requests, one can find very interesting patterns.
Here is a list of our most interesting findings:
* The time to merge pull requests is highly skewed, as can be seen in the
figure above, with the great majority of merges happening very fast. Measured in
days, 95% of the pull requests are merged in 26, 90% in 10 and 80% in 3.7 days.
30% of the pull requests are merged in under one hour!
* Pull requests are either merged fast or left open lingering before they are
* closed. Pull requests received no special treatment, irrespective whether
* they came from core team members or from the community, as there is
no statistical significant difference in the time required to close both.
* The time required to merge pull requests is not correlated with
the project's size, but it is correlated with the pull requester's track record.
The more pull requests that have been accepted by a specific developer, the
faster his/her new pull request will be processed. This is an indication that
eventually even software developers can learn to trust each other :-)
**Size**
| |
median |
80% |
90% |
95% |
| # commits |
1 |
3 |
6 |
12 |
| # Files |
2 |
7 |
17 |
36 |
| # lines changed |
20 |
168 |
497 |
1227 |
</table>
The table above speaks for itself: most pull requests
are small, touch only a few files and consequently only a few
lines. A reader well-versed in statistics will also see
that the distributions of those variables are highly skewed.
**Discussion and code review**
Once a pull request has been submitted, it is open for discussion until it is
merged or closed. The discussion is usually brief: 95% of pull requests receive
12 comments or less (80% less than 4 comments). Similarly, the number of
participants in the discussion is also low (95% of pull requests are discussed
by less than 4 people).
Code reviews are integrated in the pull request process. While the pull request
discussion can be considered an implicit form of code review, 12% of the pull
requests in our sample have also received comments on source code lines in the
included commits. This of course does not mean that the remaining pull requests
have not been code reviewed. Code reviews do not increase the probability of a
pull request being merged, but they do slow down the processing of a pull
request by an order of magnitude.
**summary:** *Most pull requests are less than 20 lines long and processed
(merged or discarded) in less than 1 day. The discussion spans on average to 3
comments, while code reviews affect the time to merge a pull request. Inclusion
of test code does not affect the time or the decision to merge a pull request.
Pull requests receive no special treatment, irrespective whether they come from
contributors or the core team.*
### What factors influence merging and time to merge?
To measure the combined effect of factors on the decision to merge a pull
request and the time it takes to do so, we employed machine learning. Given the
291 project dataset discussed above, we trained 2 classifiers, one for each
question, using 3 well known classification algorithms (logistic regression,
naive bays and random forests) without any tuning. We then calculated the mean
area under curve and accuracy metrics across random selection 10-fold cross
validation runs on the whole dataset, to select the best algorithm. Data mining
people reading this will probably laugh with our algorithm selection, but
deriving the best possible classifier was not our goal. In both cases, random
forests outperformed (by far) their two contenders. So we selected random
forests.
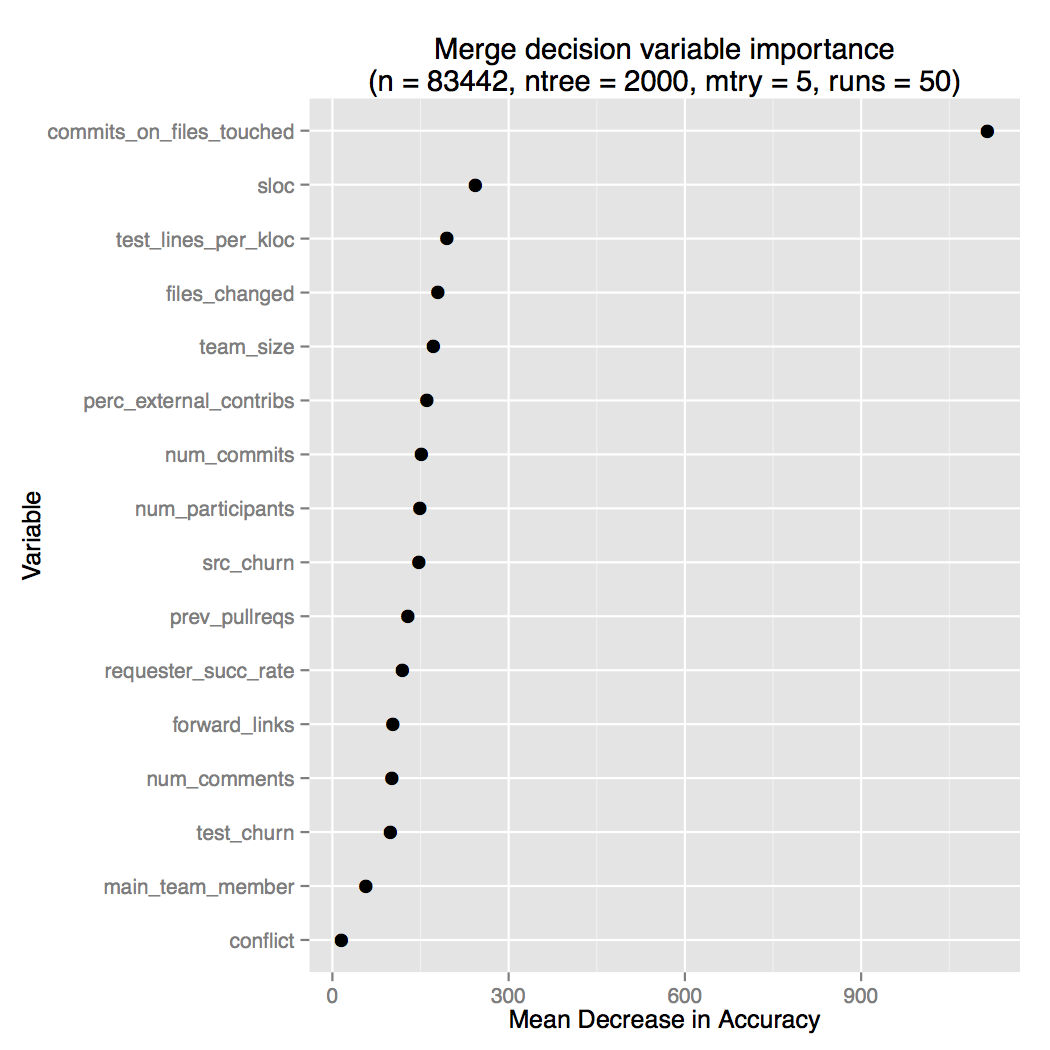
The random forest algorithm can report the relative importance of features to
the prediction outcome (the mean decrease in accuracy metric), which we used as
the result of this experiment. To estimate it we trained random forest
classifiers on half of the dataset, chosen randomly in a loop of 100 runs, but
with ridiculously high configuration parameters per (2k trees, tree depth of 5
etc). We then estimated the mean MDA per factor, as can be seen in the following
figure.
For the decision to merge a pull request, a rather unexpected factor dominates
the results: `commits_on_files_touched` which basically measures how hot is the
project area affected by the pull request. This factor is almost enough to
predict whether a pull request will be merged or not, but there is a caveat:
most pull requests are merged anyway :-)
The situation is not as clear in the time to merge a pull request. The results
are a bit fragile, as the classifier did not achieve a high accuracy score
(~70%), but are nevertheless interesting as well. So the
* track record of the contributor
* size of the project, and
* the test coverage
seem to influence the decision of how fast a pull request will be merged.
### Why are some pull requests not merged?
As most pull requests are indeed merged, it is interesting to explore why some
pull requests are *not* merged. For that reason, we manually looked into 350
pull requests that our heuristics identified as un-merged. The results can be
seen in the plot below:
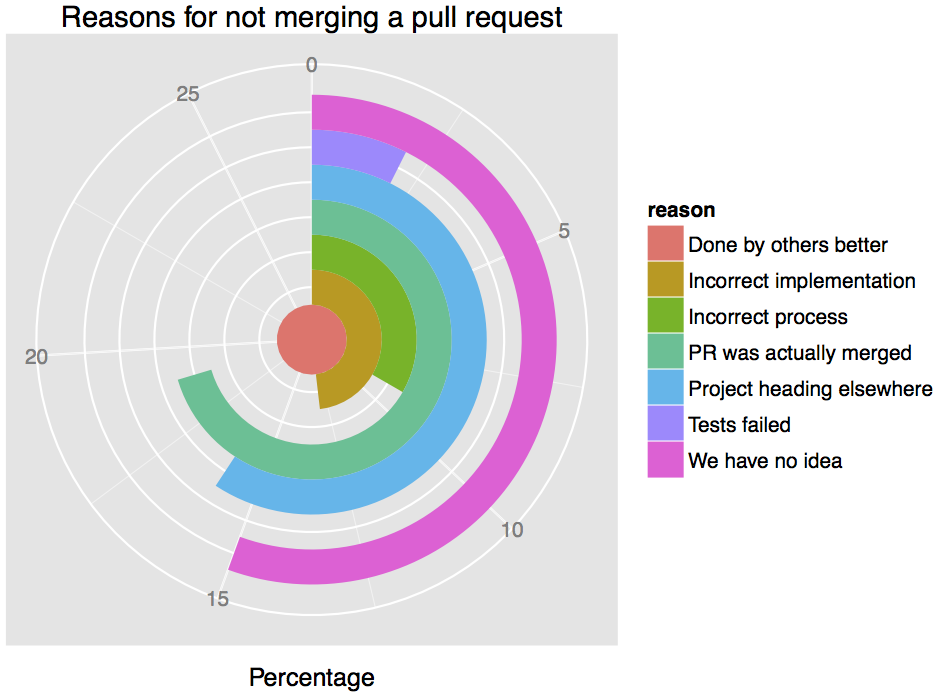 Apparently, there is no clearly outstanding reason for not merging pull
requests. If we group together close reasons that have a timing dimension, we
see that 27% of unmerged pull requests are closed due to concurrent
modifications of the code in project branches. Another 16% (superfluous,
duplicate, deferred) is closed as a result of the contributor not having
identified the direction of the project correctly and is therefore submitting
uninteresting changes. 10% of the contributions are rejected with reasons that
have to do with project process and quality requirements (process, tests); this
may be an indicator of processes not being communicated well enough or a very
rigorous code reviewing process. Finally, another 13% of the contributions are
rejected because the code review revealed an error in the implementation.
For 15% of the examined pull requests, we, as human examiners, could not
identify whether they are merged or not by looking at them. For 19%, our
inspection revealed that they were actually merged, which in turn suggests that
our merge heuristics are not inclusive enough.
The above may mean that the pull-based model (or at least the way Github
implements it) may be transparent for the project’s core team but not so much
for potential contributors. The fact that human examiners could not understand
why pull requests are rejected even after manually reviewing them supports
this hypothesis further.
**summary:** *53% of pull requests are rejected for reasons having to do with
the distributed nature of pull based development. Only 13% of the pull requests
are rejected due to technical reasons.*
### Conclusion and suggestions
The goal of this work is to obtain a deep understanding of the pull-based
software development model, as used for many important open source projects
hosted on Github. To that end, we have conducted a statistical analysis of
millions of pull requests, as well of a carefully composed set of hundreds of
thousands of pull requests from projects actively using the pull-based model.
Here are our recommendations based on our findings:
**For contributors** Want to get your contributions accepted fast? Then:
* Make them short
* Make them hot
**For project owners** Want to be effective in managing pull requests? Then:
* Invest in a comprehensive test suite
* Include pull request submission guidelines on a prominent location in your project
* Make your project roadmap clearly visible
* Ask your potential contributors to communicate their intended changes (e.g. through issues).
**For researchers and Github** Projects are struggling under a constant influx
of pull requests. Research needs to be done on tools that help developers sort
and triage incoming contributions, assess their impact on the code base and
recommends actions based on the characteristics of pull requests. For example,
an outcome of this study is that it is relatively easy to predict whether a pull
request will be merged or not, so a tool that labels pull requests as you 're gonna merge this might help
developers to focus on difficult to process pull requests.
The GHTorrent dataset is documented and distributed on [this
website](http://ghtorrent.org). The extracted datasets as well as custom-built
Ruby and R analysis tools are available on the Github repository
[gousiosg/pullreqs](https://github.com/gousiosg/pullreqs), along with
instructions on how to use them.
See the contents of this post in presentation format:
Apparently, there is no clearly outstanding reason for not merging pull
requests. If we group together close reasons that have a timing dimension, we
see that 27% of unmerged pull requests are closed due to concurrent
modifications of the code in project branches. Another 16% (superfluous,
duplicate, deferred) is closed as a result of the contributor not having
identified the direction of the project correctly and is therefore submitting
uninteresting changes. 10% of the contributions are rejected with reasons that
have to do with project process and quality requirements (process, tests); this
may be an indicator of processes not being communicated well enough or a very
rigorous code reviewing process. Finally, another 13% of the contributions are
rejected because the code review revealed an error in the implementation.
For 15% of the examined pull requests, we, as human examiners, could not
identify whether they are merged or not by looking at them. For 19%, our
inspection revealed that they were actually merged, which in turn suggests that
our merge heuristics are not inclusive enough.
The above may mean that the pull-based model (or at least the way Github
implements it) may be transparent for the project’s core team but not so much
for potential contributors. The fact that human examiners could not understand
why pull requests are rejected even after manually reviewing them supports
this hypothesis further.
**summary:** *53% of pull requests are rejected for reasons having to do with
the distributed nature of pull based development. Only 13% of the pull requests
are rejected due to technical reasons.*
### Conclusion and suggestions
The goal of this work is to obtain a deep understanding of the pull-based
software development model, as used for many important open source projects
hosted on Github. To that end, we have conducted a statistical analysis of
millions of pull requests, as well of a carefully composed set of hundreds of
thousands of pull requests from projects actively using the pull-based model.
Here are our recommendations based on our findings:
**For contributors** Want to get your contributions accepted fast? Then:
* Make them short
* Make them hot
**For project owners** Want to be effective in managing pull requests? Then:
* Invest in a comprehensive test suite
* Include pull request submission guidelines on a prominent location in your project
* Make your project roadmap clearly visible
* Ask your potential contributors to communicate their intended changes (e.g. through issues).
**For researchers and Github** Projects are struggling under a constant influx
of pull requests. Research needs to be done on tools that help developers sort
and triage incoming contributions, assess their impact on the code base and
recommends actions based on the characteristics of pull requests. For example,
an outcome of this study is that it is relatively easy to predict whether a pull
request will be merged or not, so a tool that labels pull requests as you 're gonna merge this might help
developers to focus on difficult to process pull requests.
The GHTorrent dataset is documented and distributed on [this
website](http://ghtorrent.org). The extracted datasets as well as custom-built
Ruby and R analysis tools are available on the Github repository
[gousiosg/pullreqs](https://github.com/gousiosg/pullreqs), along with
instructions on how to use them.
See the contents of this post in presentation format:
### Postscript
A couple of weeks ago, we learned that the corresponding paper was accepted in
the proceedings of the [36th](2014.icse-conferences.org/) International
Conference on Software Engineering (ICSE).
Here is a pre-print, where you can find an in
depth account of the tools and
techniques we used to come up with the results we present here.